otter使用介绍
otter
产品介绍
开源仓地址:https://github.com/alibaba/otter
基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库. 一个分布式数据库同步系统
官放介绍(入门)ppt: https://cloud.189.cn/t/Uzq6reEZ3A3m(访问码:duq6)
官放介绍(进阶)ppt:https://cloud.189.cn/t/RBraMnFz2Abi(访问码:0g2l)
整体架构
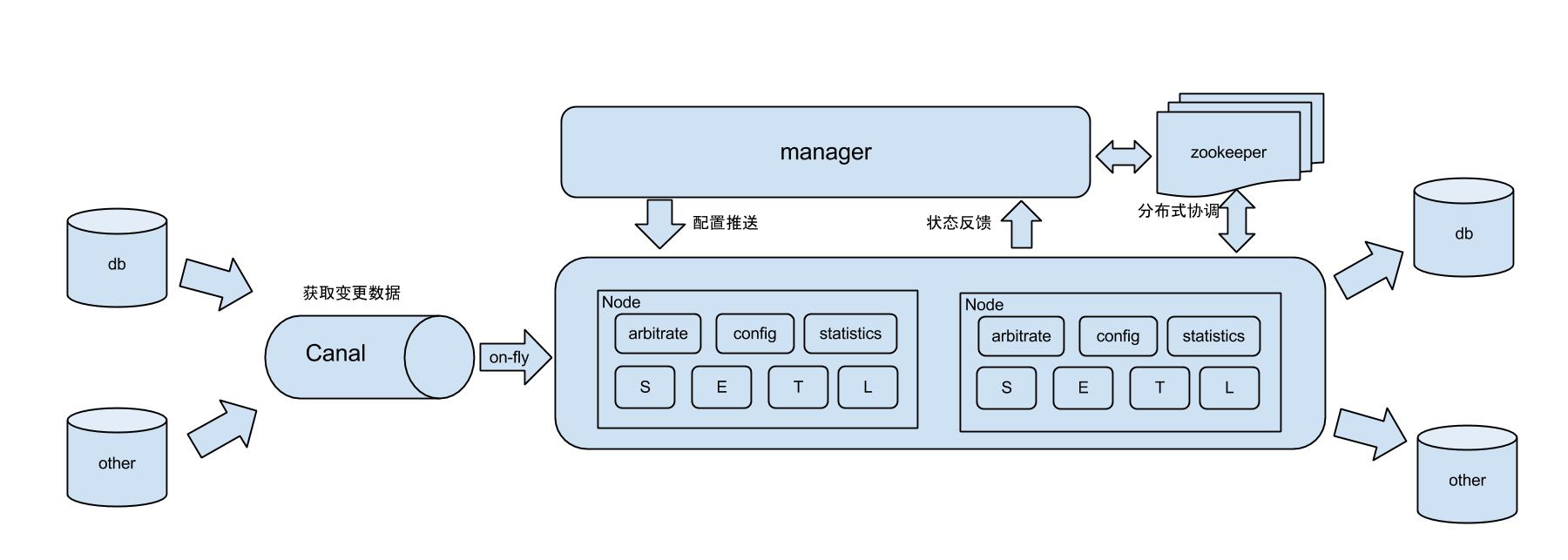
原理描述:
基于Canal开源产品,获取数据库增量日志数据。 什么是Canal, 请点击
典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点
b. node节点将同步状态反馈到manager上
- 基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作.
使用场景
1.多实例数据源、小数据量实时同步(避免重复购买DTS实时同步);
2.仅实验mysql-mysql同步,其他同步未测试。
部署方案
建议部署:
otter服务1台机器
zookeeper,最好单独部署
node单独部署,manager端可部署一个node, 承载计算公式:
数据库连接均与正式环境数据库在一个VPC下,使用内网链接
| 端口用途描述 | 默认端口号 | 添加方式 |
|---|---|---|
| Web管理端 | 8080 | 部署机外网出 |
| zookeeper | 2181 | 部署机外网出 |
使用指南
官方开源仓wiki:https://github.com/alibaba/otter/wiki
介绍很详细,在这里就不cpoy过来了,这边举例几个实际使用场景,及大数据量同步场景稳定性测试结果;
前提准备:
登录系统后,按照命名规范新建条目(不然后面越加越乱)
Zookeeper注册,集群名称命名规则:otter_zookeeper_1、otter_zookeeper_2
Node注册,集群名称命名规则:otter_node_1、otter_node_2
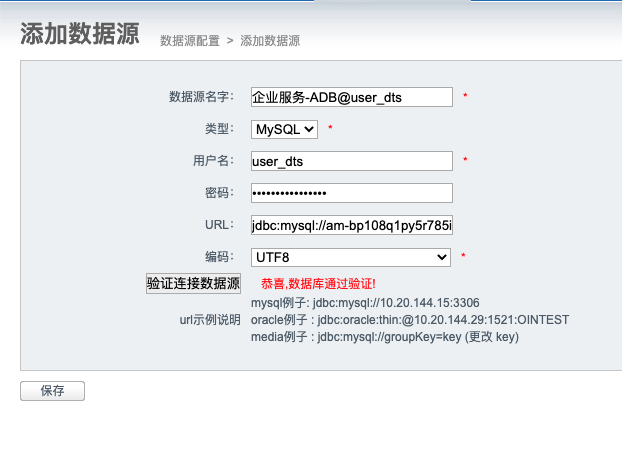
数据源添加,命名规则:项目群名称_实例命名@账号名称
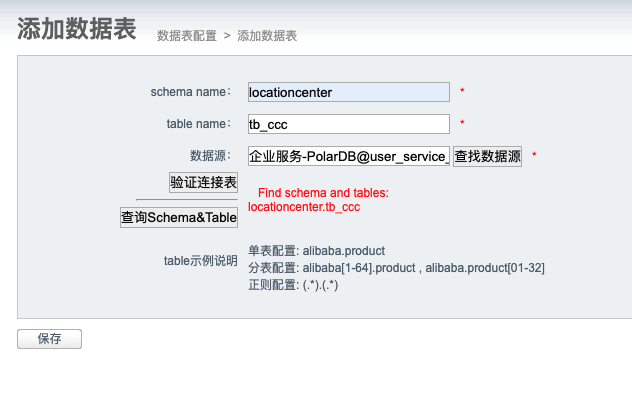
数据库表添加,按实际库表名称展示
cannal添加,命名规则:otter_canal_实例/项目群代码缩写@业务描述,同样的数据可做多份canal,即同源多分发需建多个canal
channal添加,命名规则:项目名称_业务描述,新增表同步后加同名channal并增加下划线区分()等同于阿里DTS的同步任务
注意:目标表支持ADB,使用mysql驱动,但是ADB端需手动建表(按照数仓开发规范,需审核使用方法正确性)
Pipeline添加,命名规范:单向传输即可,同一channal不能对应多个Pipeline
新增表同步实验:
1 | |
新建数据源
表名称支持正则表达式,或者直接填写.*添加全部表
注意:只读数据源需使用 _bl账号,写数据源需使用有写权限账号,最好是user_dts。


建立源表目标表



建立中途添加源表
新建channel

有需要指定时间点和binlog位置点为起点时,选中位点自定义设置,填写
1 | |
canal具体参数含义见官方wiki文档。
建立同步channel
直接同步管理-左下角,添加


具体参数可见官方wiki文档。
点击Channel名字建立Pipeline

高级设置里参数解释详见官方wiki,注意需开启 支持ddl同步选项

注意:每个canal只能提供给一个Pipeline。
点击Pipeline名称添加同步映射关系表

下一步,可编辑字段对应关系及修改字段名称

回到Channel管理界面,点击启动

1 | |

1 | |
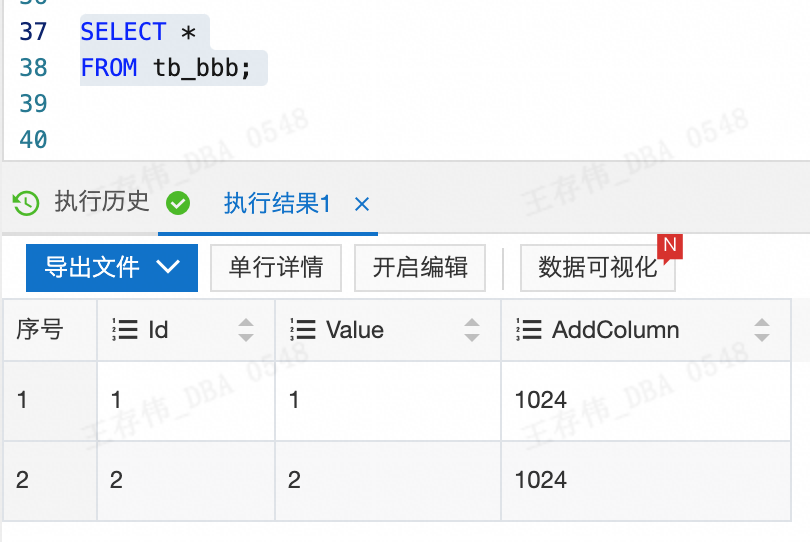
新加表同步,暂停channel,添加表映射(这里变更下目标表的表名和字段名)
1 | |




写入源表数据
1 | |
回到Channel管理,开启同步

可以看到刚才开启同步之前写入的数据已经在同步记录里了
也就是说canal支持暂停同步,添加表后再开启同步
暂停期间不支持DDL,不能修改表结构,不然重启任务后会报错,暂停期间需要占用很大ottermanager部署机器的内存空间,需短时间内完成表添加
1 | |

验证新加的表数据是否能够完成同步任务
1 | |
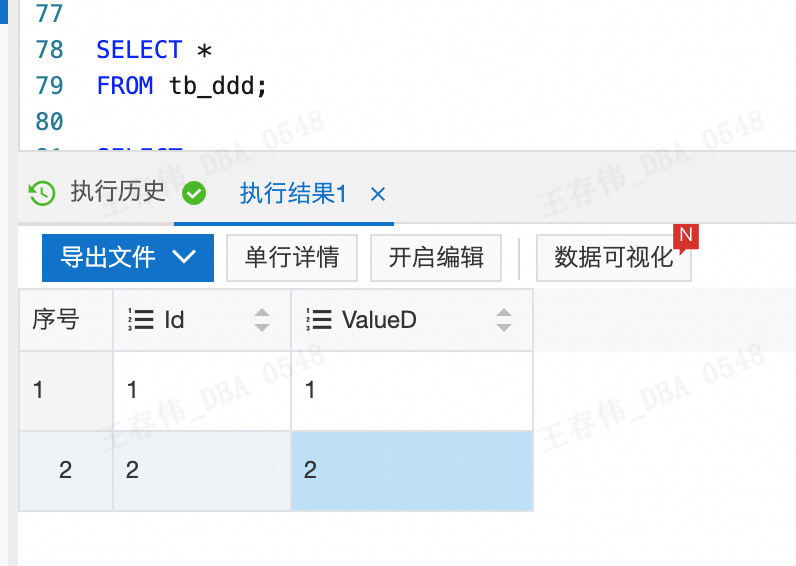
字段名称对应关系变更一定要放到下面的方框内
3.大数据量变更稳定性测试
案例1:备案中心设备状态表
变更数据量:
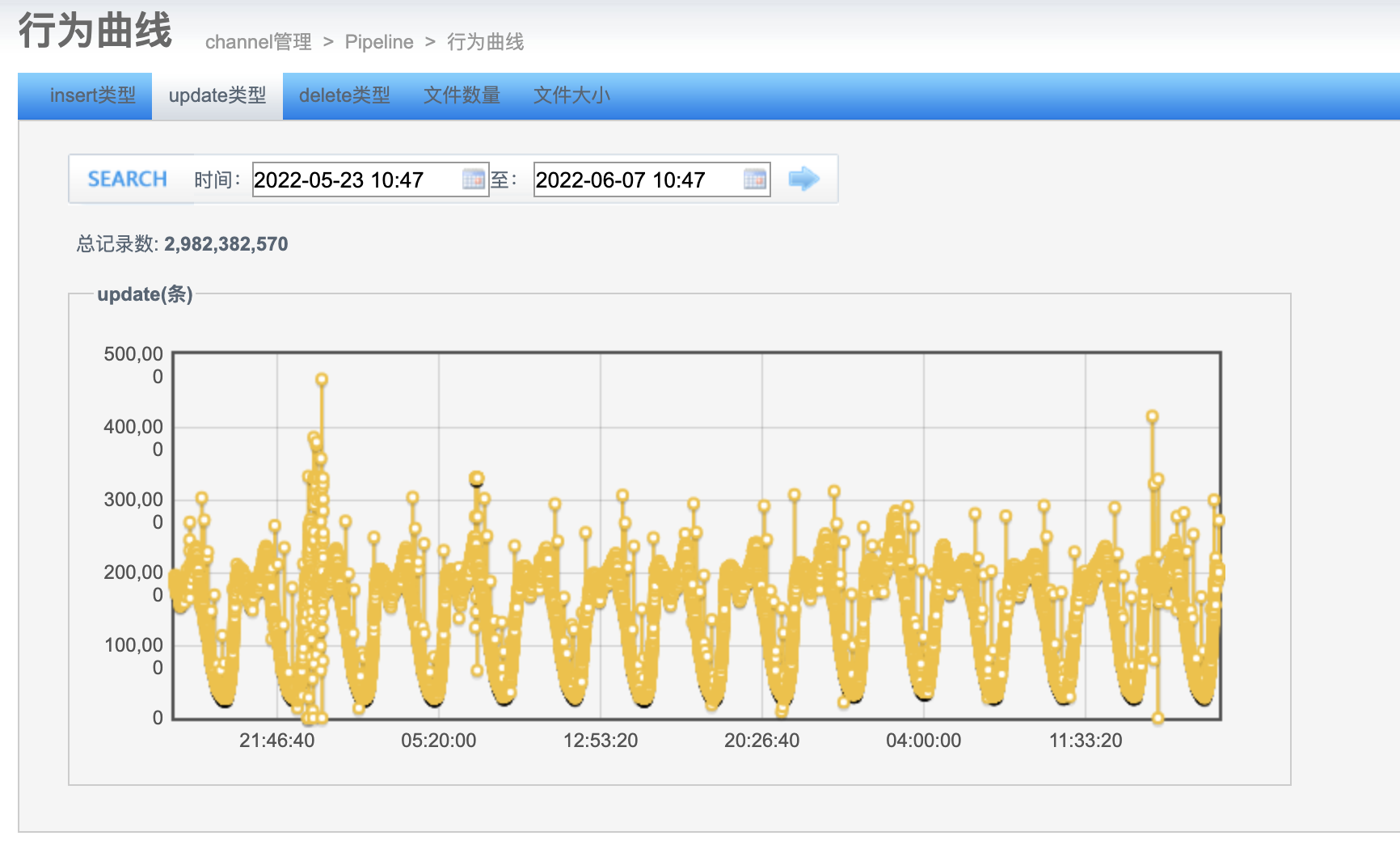
平均延迟时间
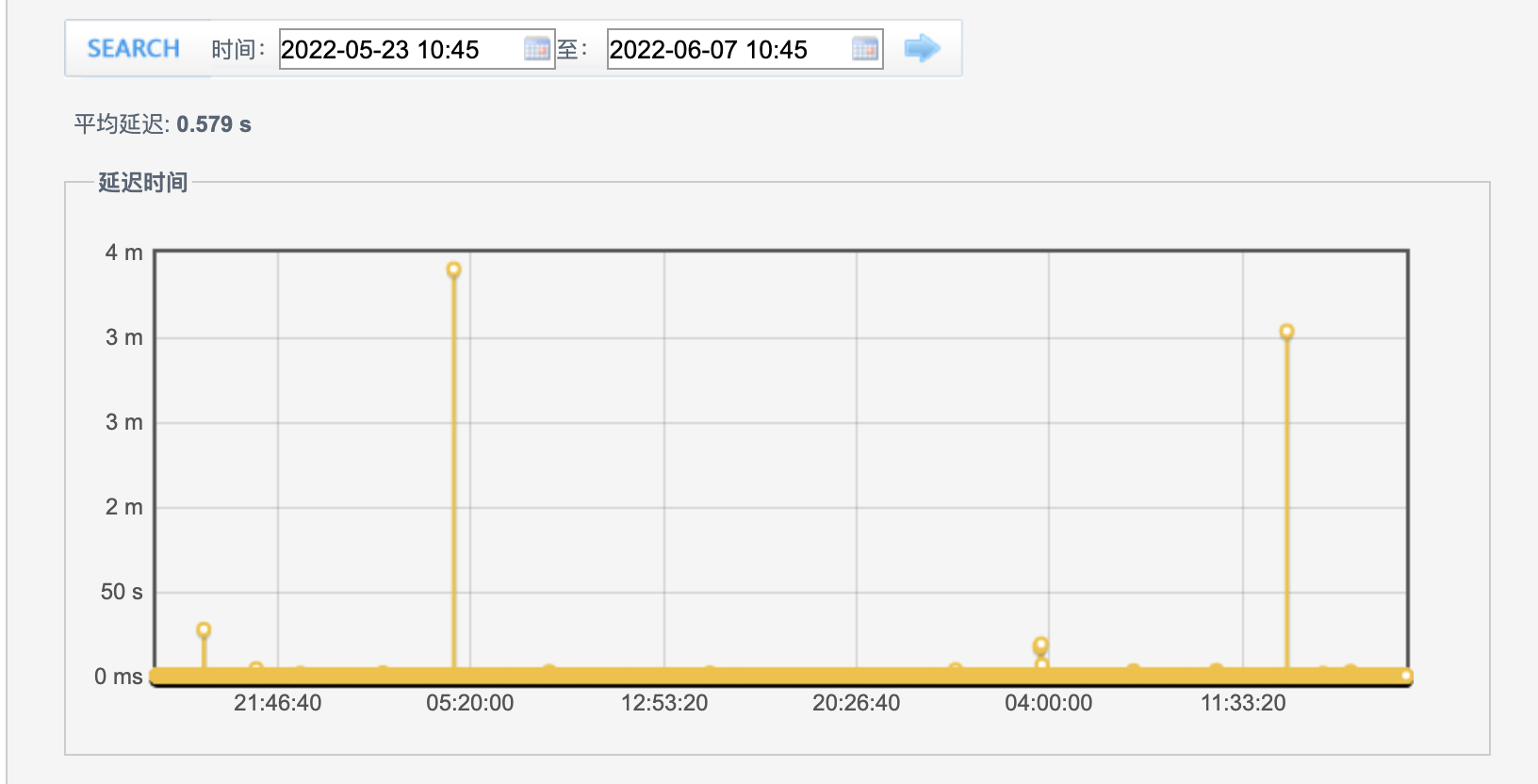
历史吞吐量

同步稳定运行半个月
案例2:客户中心配置信息实时同步,稳定运行

4.预警配置
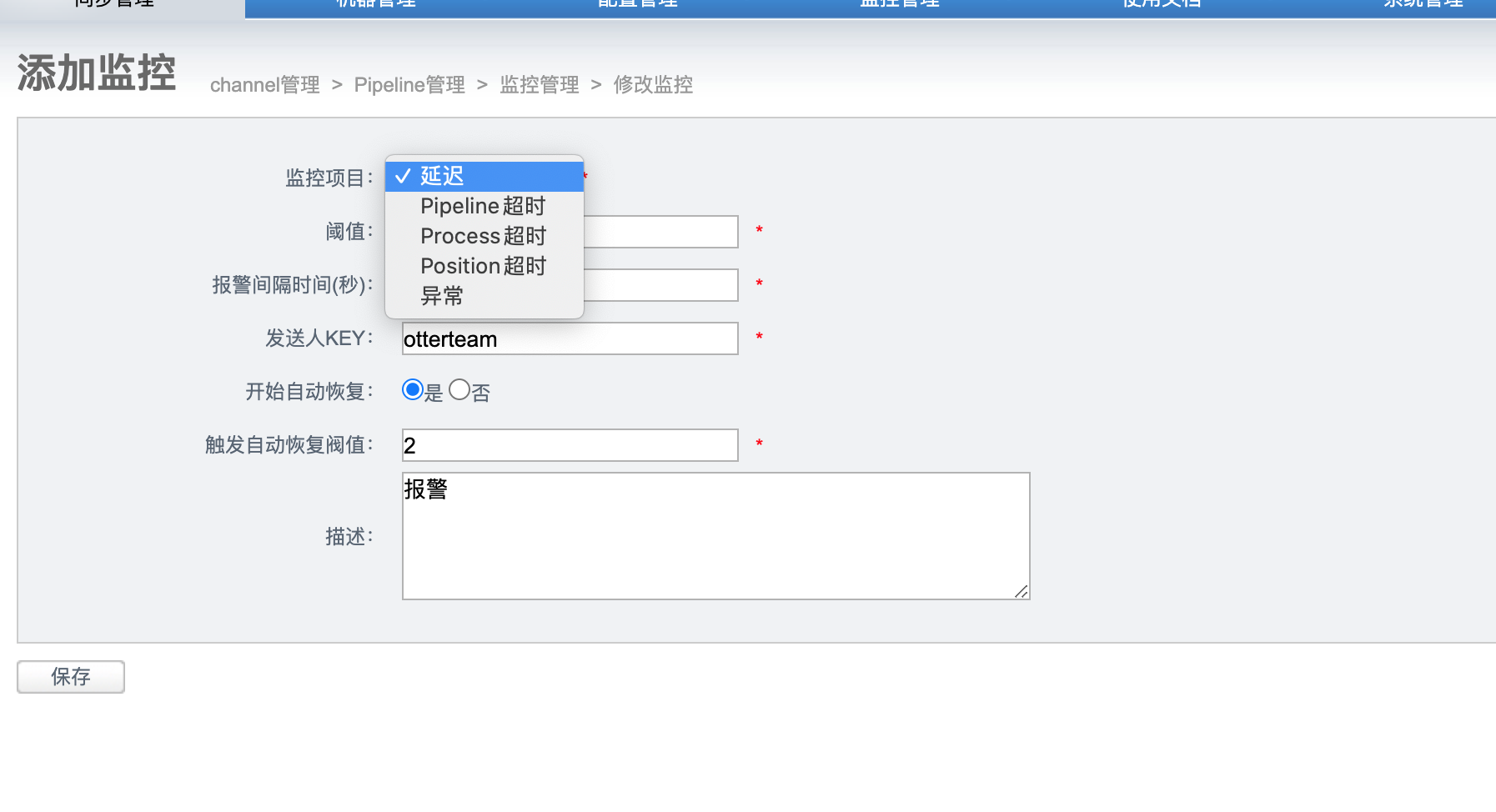
系统管理菜单下,点击系统参数设置

添加预警组后,回到Pipeline管理界面添加监控规则

5.实时数据初始化方案
方式1:
otter本身支持自动以数据同步(自由门),增量同步需用行记录模式,
主要原理:
a. 基于otter系统表retl_buffer,插入特定的数据,包含需要同步的表名,pk信息。
b. otter系统感知后会根据表名和pk提取对应的数据(整行记录),和正常的增量同步一起同步到目标库。
目前otter系统感知的自 由 门数据方式为:
- 日志记录. (插入表数据的每次变更,需要开启binlog,otter获取binlog数据,提取同步的表名,pk信息,然后回表查询整行记录)
方式2:
使用DATAX配合,先开otter启实时同步稳定后,再开启部署好的DATAX离线同步,待离线完成后,恢复otter同步。(保障otter组件canal记录的时间点在DATAX开启时间点之前即可,还要保障日志都能够读到(未释放))
目标表必需有主键,DATAX writer使用replace方式写入
FAQ
官方列举出的常见问题:https://github.com/alibaba/otter/wiki/Faq
网络资料:
Otter的限制
1 otter只支持ROW模式的数据同步,其他两种模式不支持
2 源库只支持mysql,目标库支持mysql和oracle
3 同步的表必须要有主键,无主键表update会是一个全表扫描,效率比较差),就是全字段匹配,如果出现重复记录的话,同步会导致数据错乱
4 支持部分ddl同步 (支持create table / drop table / alter table / truncate table / rename table / create index / drop index,其他类型的暂不支持,比如grant,create user,trigger等等),同时ddl语句不支持幂等性操作,所以出现重复同步时,会导致同步挂起,可通过配置高级参数:跳过ddl异常,来解决这个问题
5 otter ddl同步不支持异构处理,库名、表名都要求一致
6 不支持带外键的记录同步. (数据载入算法会打散事务,进行并行处理,会导致外键约束无法满足)
7 数据库上trigger配置慎重. (比如源库,有一张A表配置了trigger,将A表上的变化记录到B表中,而B表也需要同步。如果目标库也有这trigger,在同步时会插入一次A表,2次B表,因为A表的同步插入也会触发trigger插入一次B表,所以有2次B表同步.)
8 2个manager,可以部署2个manager,manager之间本身没有通信,而是通过zk和数据库,配置node的时候需要知道manager,可以指定其中一个即可,数据会反应到数据库和zk中,但是当这个manager挂了,新配置的node信息就不能反馈到另外一个manager上,所以最佳实践是指定所有的manage
常见故障处理
1 异构环境下(源与目标库名表名有一个不相同),主库执行DDL导致同步挂起,此时可跳过DDL同步进行恢复,将源库执行的DDL SQL手动执行到目标库。
2 网络中断导致同步挂起,此时可重启服务器对应node节点进行恢复。
3 其他问题,可通过修改canal post位点或者重新同步进行解决。
4 Channel挂起或暂停已超源实例MySQLbinlog清理时间,可初始化其同步进度重新从某时间点开始继续同步,但需要做一次离线同步。
